

Introduction
Natural Language Processing (NLP) is a field of Artificial Intelligence (AI) that enables computers to understand, interpret, and generate human language (text, image or speech) in a meaningful way. It allows machines to process language data and interact with humans in a more natural and intelligent manner.
In this technical blog, we will be learning the fundamental concepts of NLP, how language data is processed, analysed, and transformed into structured formats that machines can understand.
Get the complete introduction-to-nlp.ipynb and follow along at your own pace.
After downloading the notebook, choose your preferred environment:
- Make sure Python is installed. If not, download it from python.org.
- Open a terminal and install Jupyter:
pip install notebook - Navigate to the folder where you saved the notebook:
cd path/to/your/folder - Launch Jupyter:
jupyter notebook - In the browser tab that opens, click introduction-to-nlp.ipynb to open it.
- Run cells one by one using Shift + Enter or click Run All from the Cell menu.
 Google Colab
Google Colab
- Go to colab.research.google.com.
- Click File → Upload notebook.
- Select the downloaded introduction-to-nlp.ipynb file.
- The notebook will open in your browser — no local installation needed.
- Run cells with Shift + Enter or click Runtime → Run all.
- Download and install Visual Studio Code.
- Install the Jupyter extension from the VS Code Extensions marketplace.
- Open VS Code, then open the folder containing the notebook via File → Open Folder.
- Click on introduction-to-nlp.ipynb in the file explorer to open it.
- Select a Python kernel (VS Code will prompt you) and run cells with Shift + Enter.
Tip: Install the required packages before running — the notebook includes a cell at the top with all the pip install commands you need.
Components of NLP
NLP is divided into two components as follows:
- Natural Language Understanding (NLU) - It is a subset of NLP that focuses on machine comprehension. It takes unstructured text (like speech or a text) and converts it into structured data, identifying user intent, sentiment, and context.
- Natural Language Generation (NLG) - It is a subset of NLP that focuses on producing output. It takes structured data and converts it into conversational human language.
Levels of NLP
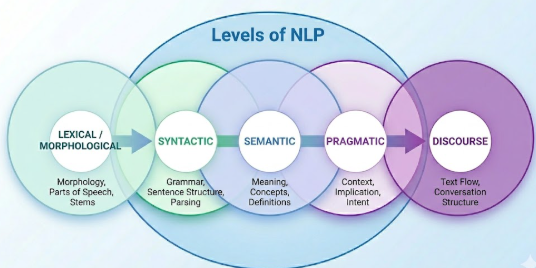
- Syntactic analysis: is the process of analyzing the grammatical structure of a sentence, ensuring words are arranged correctly according to grammar rules.
- Semantic analysis: it involves understanding the meaning of words, phrases, and sentences in context.
- Lexical analysis: it is the process of breaking text into individual words (tokens) and understanding their basic form and meaning.
- Discourse analysis: it is the process of understanding how multiple sentences connect to form a coherent meaning.
- Pragmatic analysis: it is the study of meaning in context. It looks at how the same sentence can mean different things depending on who is saying it, where they are etc.
Data processing in NLP
- Lowercasing: Involves converting all the text into lowercase so that the algorithm does not treat the same words in different cases as different. Example: Book, book,BOOK
- Stopword removal: Stopwords are words that appear very frequently but carry little important meaning. They are removed to enable the models focus on the more meaningful words in the text/corpus.
- Part of speech tagging:: It is the process of labeling every word in a corpora with its corresponding grammatical category such as nouns, verbs, adjectives, adverbs, etc.
- Stemming: It is a process of reducing words to their root or base form by cutting of prefixes or suffixes. It helps in normalizing text by treating different forms of a word (e.g. running, runs) as the same word ("run"). However the the result may not always be a real word, example studies - stud
- Lemmatization: it is the process of converting a word to its meaningful base or dictionary form, called a lemma and ensuring the root word is linguistically correct.
import nltk
nltk.download('punkt')
tokens = nltk.word_tokenize("Natural Language Processing is fascinating!")
print(tokens)
# ['Natural', 'Language', 'Processing', 'is', 'fascinating', '!']Text Representation
Bag of Words (BoW) is a way of converting text into numbers by counting how many times each word appears.
TF-IDF (Term Frequency - Inverse Document Frequency)
It is a method used to measure how important a word is in a document compared to a collection of documents. It improves BoW by giving importance to meaningful words and reducing the weight of very common ones.
Term Frequency (TF): How often a word appears in a document.
$$TF = \frac{\text{word count in document}}{\text{total words in document}}$$
Inverse Document Frequency (IDF): How unique a word is across all documents.
$$IDF = \log \left( \frac{\text{total documents}}{\text{documents containing the word}} \right)$$
TF-IDF = TF x IDF
Applications of NLP
- Sentiment Analysis: NLP is used to determine the emotional tone of a text, such as positive, negative, or neutral. It helps understand people’s opinions, feelings, or attitudes from written data like reviews or social media posts.
- Name Entity Recognition: It involves identifies and extracts important entities from text like names of people, locations, organizations, dates, etc. NER is widely used in applications like search engines, chatbots, and information extraction systems.
- Text Classification: It involves assigning predefined categories to text, such as spam, positive/negative sentiment, or topic label. it can be used in areas such as spam detection, news categorization, etc.
- Text Summarization: It is the process of shortening long texts while preserving the main ideas and key information.
- Machine Translation: It involves translating context from one language to another.
- Speech Recognition Systems: It is the process of converting spoken language into written text and vice versa.

