TUNUH: Multilingual Health Large Language Model for Low Resource African Languages
Background
Large Language Models (LLMs) are advanced artificial intelligence systems trained on vast amounts of data to understand and generate human-like language. They play a crucial role in various Natural Language Processing (NLP) applications, such as machine translation, text generation, speech recognition, and summarization.
However, most existing LLMs are primarily trained on high-resource languages, leaving low-resource languages underrepresented. This imbalance creates a major barrier to digital inclusion, particularly for underserved communities, as speakers of local languages are often excluded from benefiting fully from technological advancements.
This project aims to address this gap by developing a multilingual health LLM tailored for diabetes in low-resource African languages. It seeks to enhance healthcare accessibility by enabling patients to access reliable health information, communicate effectively with healthcare providers, and receive care in their native languages.
Accomplishments
- Contribution to the African Next Voices (ANV) project through the collection and annotation of Kikuyu text and speech data.
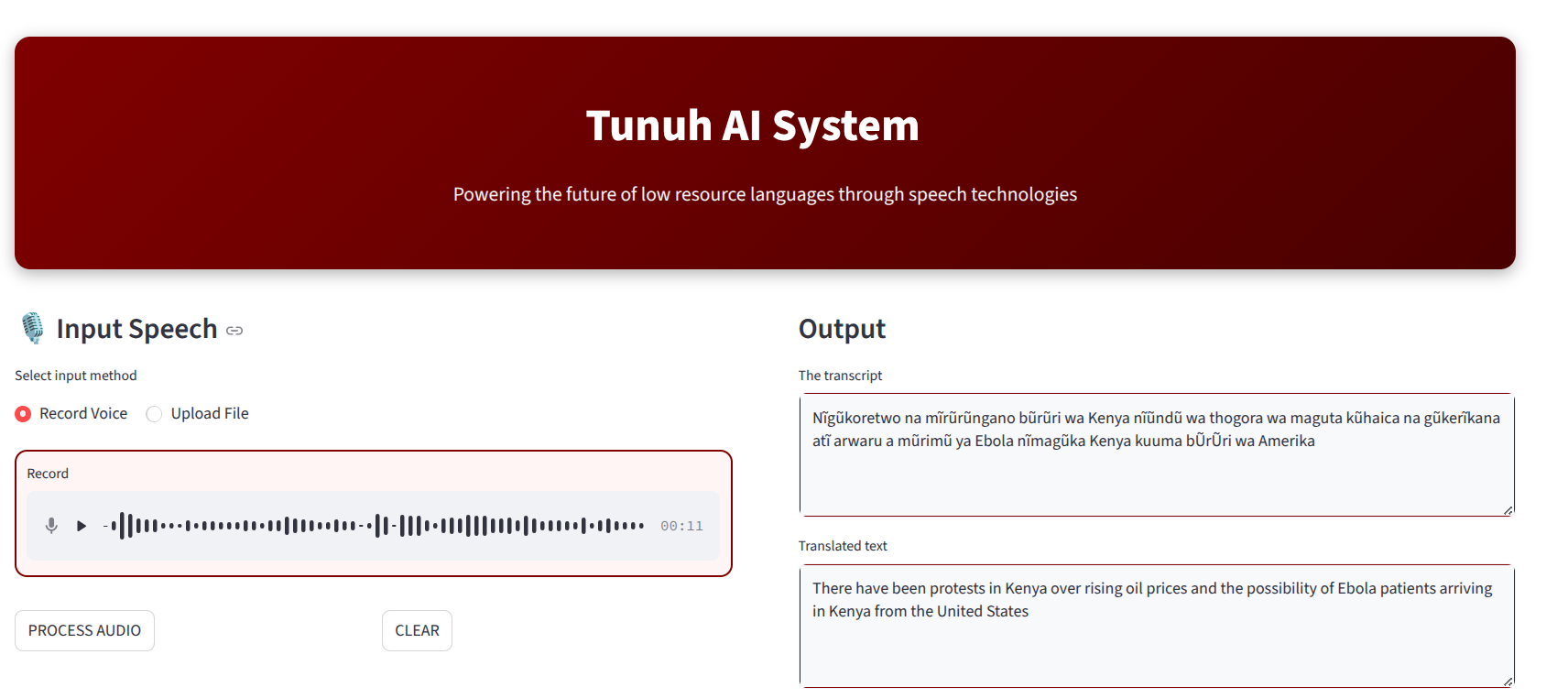
- Development of the Tunuh model, an automatic speech aware system with speech-to-text and translation capabilities, fine-tuned on Kikuyu speech and text datasets. This model provides the foundational framework for the diabetes focused health system.
Next Steps
Data collection for diabetes text and speech data to support the fine-tuning of the model into a more specialized, domain specific diabetes health system.