CAMERA TRAP APPLICATION
Camera Trap Application
Introduction
Camera traps are a widely used tool in wildlife conservation. They are used to monitor animal
populations and gather data on animal behaviour. However, the large amount of data generated by
camera traps makes it difficult to process and analyse the data.
In this second part, we will develop a machine learning model that can automatically classify
animal
species captured by camera traps in the Dedan Kimathi University Wildlife Conservancy.
By achieving this, we hope to gain valuable insights into animal behaviour and contribute to
wildlife conservation efforts.
Data Preparation
In this section, we’ll extract the data given and prepare it for analysis.We’ll do this by splitting the data into training, validation and test sets. Splitting data into training, validation, and test sets is essential as it helps assess the performance of a model by providing a way to train the model on one portion of the data, tune its parameters on another (validation set), and finally evaluate its generalization on unseen data (test set), which helps avoid overfitting and ensures the model's reliability.
Steps¶
- Unzip the dataset
- Split the dataset into train, validation and test sets
- From the metadata build the train, validation and test images and labels folders
- Load the Images from directory
# The Modules required for this tutorial
from modules_used import *
# Extract the dataset to the current working directory
with zipfile.ZipFile('./dataset.zip', 'r') as zip:
zip.extractall(f'{os.getcwd()}')
print('Dataset extracted successfully!')
# load the train and test metadata
data_dir = os.path.join(os.getcwd(), 'dataset')
train_metadata_path = os.path.join(data_dir, 'train.csv')
test_metadata_path = os.path.join(data_dir, 'test.csv')
# read the data
train_df = pd.read_csv(train_metadata_path)
test_df = pd.read_csv(test_metadata_path)
# classes to use for training
classes = ['IMPALA', 'WARTHOG', 'ZEBRA']
# filter the train and test sets to only include the desired classes
train_df = train_df[train_df['Species'].isin(classes)]
test_df = test_df[test_df['Species'].isin(classes)]
# split the train set to train and validation sets
train_df, val_df = train_test_split(train_df, test_size=0.12, random_state=42)
# the length of all the sets
sets_len = len(train_df) + len(val_df) + len(test_df)
# print the length of each set
print(f'Train set length: {len(train_df)}, {len(train_df)/sets_len*100:.2f}%')
print(f'Validation set length: {len(val_df)}, {len(val_df)/sets_len*100:.2f}%')
print(f'Test set length: {len(test_df)}, {len(test_df)/sets_len*100:.2f}%')
# build the image datasets
train_dir = os.path.join(data_dir, 'train') # location of the training data
val_dir = os.path.join(data_dir, 'train') # location of the validation data
test_dir = os.path.join(data_dir, 'test') # location of the test data
# create the training, validation and test directories
helper.split_data(train_dir, train_df, 'train')
helper.split_data(val_dir, val_df, 'val')
helper.split_data(test_dir, test_df, 'test')
Train set length: 1368, 79.08% Validation set length: 187, 10.81% Test set length: 175, 10.12%
train_images_path = 'train'
val_images_path = 'val'
test_images_path = 'test'
# Visualize the data distribution
helper.data_distribution(train_images_path, val_images_path, test_images_path, plot=True)

Neural Networks
Deep Learning is based on artificial neural networks which have been around in some form since the late 1950s. The networks are built from individual parts approximating neurons, typically called units or simply "neurons." Each unit has some number of weighted inputs. These weighted inputs are summed together (a linear combination) then passed through an activation function to get the unit's output.
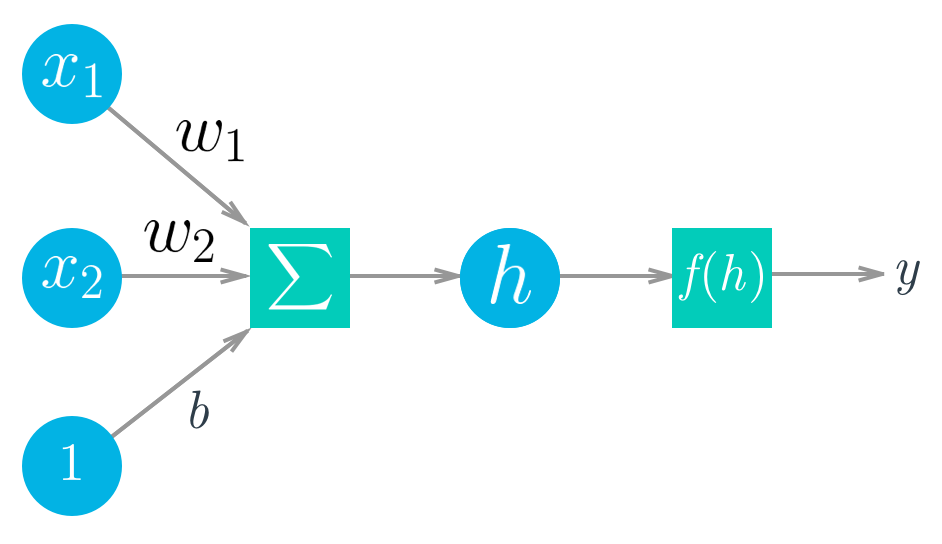
Mathematically this looks like:
$$ \begin{align} y &= f(w_1 x_1 + w_2 x_2 + b) \\ y &= f\left(\sum_i w_i x_i +b \right) \end{align} $$With vectors this is the dot/inner product of two vectors:
$$ h = \begin{bmatrix} x_1 \, x_2 \cdots x_n \end{bmatrix} \cdot \begin{bmatrix} w_1 \\ w_2 \\ \vdots \\ w_n \end{bmatrix} $$Tensors
It turns out neural network computations are just a bunch of linear algebra operations on *tensors*, a generalization of matrices. A vector is a 1-dimensional tensor, a matrix is a 2-dimensional tensor, an array with three indices is a 3-dimensional tensor (RGB color images for example). The fundamental data structure for neural networks are tensors and Tensorflow (as well as pretty much every other deep learning framework) is built around tensors.BATCH_SIZE = 3
IMG_SIZE = (96, 96)
# Load the images to tensors
train_tensors = helper.load_images_from_dir(train_images_path, BATCH_SIZE, IMG_SIZE, shuffle=True)
val_tensors = helper.load_images_from_dir(val_images_path, BATCH_SIZE, IMG_SIZE, shuffle=False)
test_tensors = helper.load_images_from_dir(test_images_path, BATCH_SIZE, IMG_SIZE, shuffle=False)
# extract the images and labels
train_images, train_labels = helper.extract_images_and_labels(train_tensors, normalize=True, categorical=True)
val_images, val_labels = helper.extract_images_and_labels(val_tensors, normalize=True, categorical=True)
test_images, test_labels = helper.extract_images_and_labels(test_tensors, normalize=True, categorical=True)
# Define the labels dictionary
labels = {
0: 'IMPALA',
1: 'WARTHOG',
2: 'ZEBRA'
}
# Visualize the images
helper.visualize_images(train_tensors, BATCH_SIZE, class_names=list(labels.values()))
Found 1368 files belonging to 3 classes. Found 187 files belonging to 3 classes. Found 175 files belonging to 3 classes.

Data Augmentation
This is a technique of artificially increasing the training set by creating modified copies of a dataset using existing data.The validation and testing sets are used to measure the model's performance on data it hasn't seen yet. For this you don't want any scaling or rotation transformations
data_augmentation = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'),
tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),
tf.keras.layers.experimental.preprocessing.RandomZoom(0.2),
tf.keras.layers.experimental.preprocessing.RandomContrast(0.2),
tf.keras.layers.experimental.preprocessing.RandomTranslation(0.2, 0.2)
])
# augment the train tensors from directory
# Apply data augmentation to train tensors
augmented_train_tensors = train_tensors.map(lambda x, y: (data_augmentation(x, training=True), y))
# extract the augmented train images and labels
augmented_train_images, augmented_train_labels = helper.extract_images_and_labels(augmented_train_tensors, normalize=True, categorical=True)
# visualize the augmented images
helper.visualize_images(augmented_train_tensors, BATCH_SIZE, class_names=list(labels.values()))

Feature Distribution
# Call the function with your train_images, train_labels, and labels
helper.visualize_dimensionality_reduction(train_images, train_labels, labels)

Model Development
Leveraging Transfer Learning, we will use a pre-trained model to develop our model. We will use the MobileNet model which is a lightweight model that is suitable for mobile and embedded vision applications. We will use the pre-trained model and add a few layers to it to make it suitable for our application.# Model Architecture leveraging pretrained weights
LEARNING_RATE = 0.005
NUM_CLASSES = 3
DROPOUT = 0.1
WEIGHT_DECAY = 0.00000
ACTIVATION = 'softmax'
OPTIMIZER = 'adam'
MOMENTUM = 0.9
model = helper.build_model(num_classes=NUM_CLASSES, dropout=DROPOUT,
weight_decay=WEIGHT_DECAY, activation=ACTIVATION,
optimizer=OPTIMIZER, momentum=MOMENTUM,
learning_rate=LEARNING_RATE)
Defining Callbacks
Monitoring the minimum validation loss and saving the model with the lowest validation loss. We will use the ModelCheckpoint callback to save the model with the lowest validation loss.We will reduce the learning rate when the validation loss has stopped improving using the ReduceLROnPlateau callback after monitoring for 5 eopchs then reduce by half.
We will stop training the model when the validation loss has stopped improving using the EarlyStopping callback after monitoring for 15 epochs.
EPOCHS = 100
CHECKPOINT_PATH = 'model.h5'
MONITOR = 'val_loss'
MODE = 'min'
PATIENCE = 5 # number of epochs with no improvement after which learning rate will be reduced.
FACTOR = 0.5 # factor by which the learning rate will be reduced. new_lr = lr * factor
# defining the callbacks
callbacks = helper.define_callbacks(checkpoint_path=CHECKPOINT_PATH,
monitor=MONITOR, mode=MODE,
patience=PATIENCE, factor=FACTOR)
# Train the model
history = model.fit(
augmented_train_images,
augmented_train_labels,
epochs=EPOCHS,
validation_data=(val_images, val_labels),
verbose=2,
callbacks=callbacks
)

15/15 - 1s - loss: 0.3095 - accuracy: 0.8772 - val_loss: 0.2974 - val_accuracy: 0.9206 - lr: 1.5625e-04 - 1s/epoch - 71ms/step
Model Evaluation
Evaluating machine learning models for image classification is crucial as it determines how accurately they can categorize images. This evaluation process provides valuable insights into a model's performance by measuring its ability to correctly identify objects or patterns in images.Classification Report
Accuracy¶
Accuracy is the most intuitive performance measure and it is simply a ratio of correctly
predicted
observation to the total observations.
Precision¶
Precision is a measure of how many of the positive predictions made are correct (true
positives).
Recall¶
Recall is a measure of how many of the positive cases the classifier correctly predicted, over
all
the positive cases in the data.
For more information on the classification report, check out this link.
# evaluate the best saved model
model = tf.keras.models.load_model('model.h5')
print(model.evaluate(test_images, test_labels))
helper.plot_classification_report(model, test_tensors, labels)
2/2 [==============================] - 1s 33ms/step - loss: 0.8017 - accuracy: 0.8644 [0.8016550540924072, 0.8644067645072937] 2/2 [==============================] - 1s 33ms/step

Sanity Check
We will use the model to predict the class of a random image from the test set. We will then plot the image and the predicted class to see if the model is working as expected.helper.inference_model(model, mapping=labels)
Class: ZEBRA 1/1 [==============================] - 0s 34ms/step

Model Quantization
Quantization is a model size reduction technique that converts model weights from high-precision floating-point representation to low-precision floating-point (FP) or integer (INT) representationsWe will use the TFLiteConverter to convert the model to a TFLite model and then quantize it to reduce the model size we'll convert from the default float32 to int8 supported by the OpenMV Cam which is our target device.
We'll then assess the performance of the quantized model.
def representative_dataset_generator():
for data, _ in train_tensors:
yield [data] # shape: (batch_size, height, width, channels)
# load the best model
model = tf.keras.models.load_model('model.h5')
# quantizing the model to int8
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.representative_dataset = representative_dataset_generator
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = [tf.dtypes.int8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
hub_m = converter.convert()
# save the keras model
with open('model.tflite', 'wb') as f:
f.write(hub_m)
# evaluate the tflite model
print('Evaluating tflite model...')
helper.evaluate_tflite('model.tflite', test_tensors, dtype='int8')
INFO:tensorflow:Assets written to: C:\Users\Austin\AppData\Local\Temp\tmpg415r5r8\assets
INFO:tensorflow:Assets written to: C:\Users\Austin\AppData\Local\Temp\tmpg415r5r8\assets
Model Profiling
We will use the Edge Impulse API for this case to evaluate the performance on the target deviceimport edgeimpulse as ei
import json
# add the api key to edge impulse
with open('config.json') as f:
config = json.load(f)
api_key = config['edge_impulse_api_key']
ei.API_KEY = api_key
# the supported devices
profile_devices = ei.model.list_profile_devices()
print(profile_devices)
# target device is open mv cam h7 plus
model_profile = ei.model.profile(model='model.tflite')
# Profiling the model to check the compatibility with the MCU
model_profile.summary()
Model Deployment
In this section we'll deploy the model to the OpenMV Cam and test it on the device. We'll write our classes to a labels.txt file that will be read by the OpenMV Cam to display the predicted class during inferencing.# Write the class names to text file
with open('labels.txt', 'w') as f:
for item in list(train_tensors.class_names):
f.write("%s\n" % item)
# create a folder called openmv-model if it doesn't exist
if not os.path.exists('openmv-model'):
os.mkdir('openmv-model')
# move the tflite file and labels.txt file into the openmv-model folder
os.rename('mobileweights_6classes4.tflite', 'openmv-model/trained449.tflite')
'''Uncomment and run this once if the file does not exist'''
# os.rename('labels.txt', 'openmv-model/labels.txt')
# evaluate the performance of the tflite model
helper.evaluate_tflite('openmv-model/trained449.tflite', test_tensors, dtype='int8')
0.5423728813559322